Microservice related
Last updated: 2023, Feb 26
微服务架构是什么? - 老刘的回答 - 知乎
link: https://www.zhihu.com/question/65502802/answer/802678798 微服务架构 = 80% 的 SOA 服务架构思想 + 100% 的组件化架构思想 + 80% 的领域建模思想
最初的需求
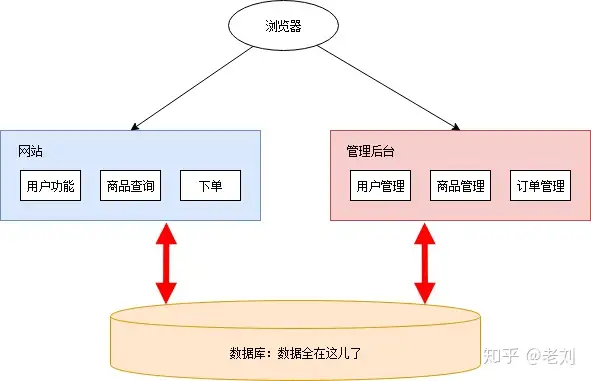
随着业务发展
 这一阶段存在很多不合理的地方:
这一阶段存在很多不合理的地方:
- 网站和移动端应用有==很多相同业务逻辑的重复代码==。
- 数据有时候通过数据库共享,有时候通过接口调用传输。接口调用关系杂乱。
- 单个应用为了给其他应用提供接口,渐渐地越改越大,包含了很多本来就不属于它的逻辑。应用边界模糊,==功能归属混乱==。
- 管理后台在一开始的设计中保障级别较低。加入数据分析和促销管理相关功能后出现性能瓶颈,影响了其他应用。
- 数据库表结构被多个应用依赖,==无法重构和优化==。
- 所有应用都在一个数据库上操作,数据库出现性能瓶颈。特别是数据分析跑起来的时候,数据库性能急剧下降。
- 开发、测试、部署、维护愈发困难。即使==只改动一个小功能,也需要整个应用一起发布==。有时候发布会不小心带上了一些未经测试的代码,或者修改了一个功能后,另一个意想不到的地方出错了。为了减轻发布可能产生的问题的影响和线上业务停顿的影响,所有应用都要在凌晨三四点执行发布。发布后为了验证应用正常运行,还得盯到第二天白天的用户高峰期……
- 团队出现推诿扯皮现象。关于一些==公用的功能应该建设在哪个应用上==的问题常常要争论很久,最后要么干脆各做各的,或者随便放个地方但是都不维护。
是时候做出改变了
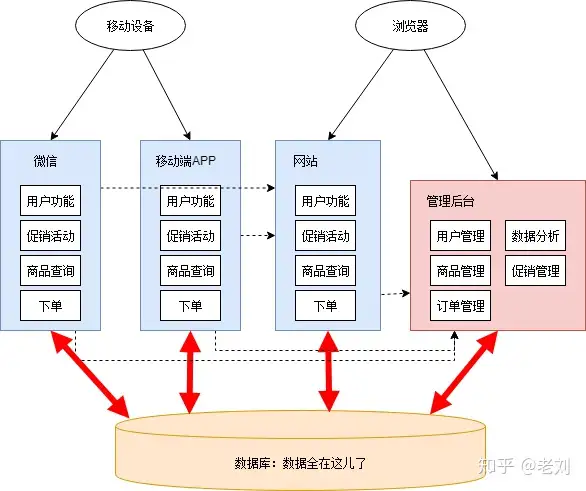
 这个阶段只是将服务分开了,数据库依然是共用的,所以一些烟囱式系统的缺点仍然存在:
这个阶段只是将服务分开了,数据库依然是共用的,所以一些烟囱式系统的缺点仍然存在:
- 数据库成为性能瓶颈,并且有单点故障的风险。
- 数据管理趋向混乱。即使一开始有良好的模块化设计,随着时间推移,==总会有一个服务直接从数据库取另一个服务的数据的现象==。
- ==数据库表结构可能被多个服务依赖==,牵一发而动全身,很难调整。
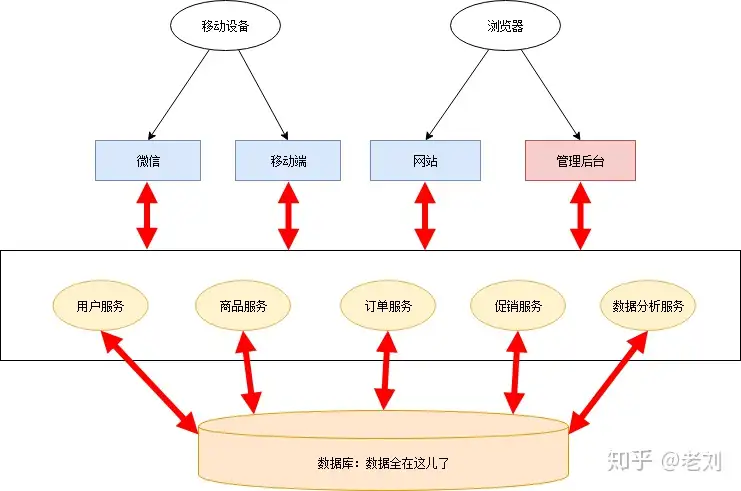
数据库也拆开
如果一直保持共用数据库的模式,则整个架构会越来越僵化,失去了微服务架构的意义。因此小明和小红一鼓作气,把数据库也拆分了。==所有持久化层相互隔离,由各个服务自己负责==。另外,为了提高系统的实时性,加入了消息队列机制。架构如下:
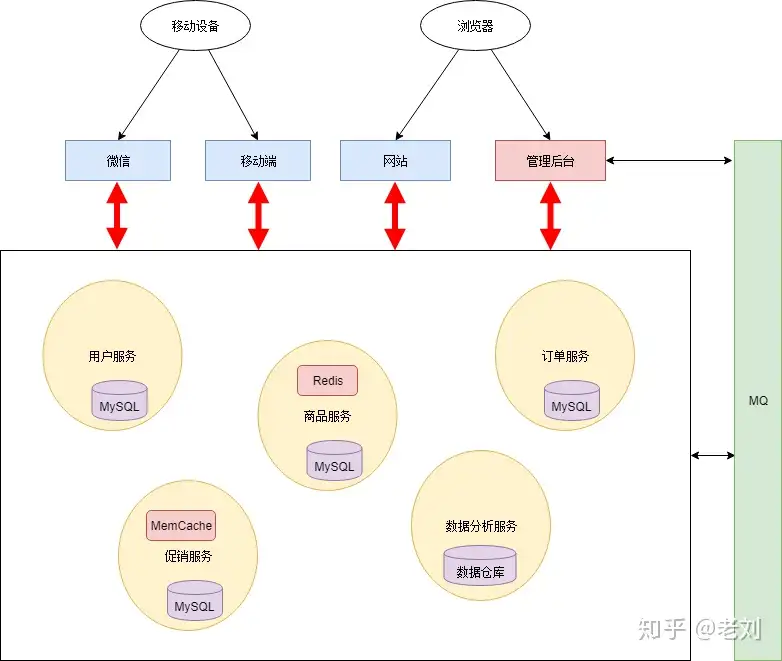
没有银弹
微服务架构虽然解决了旧问题,也引入了新的问题:
- 微服务架构整个应用分散成多个服务,定位故障点非常困难。
- 稳定性下降。服务数量变多导致其中一个服务出现故障的概率增大,并且一个服务故障可能导致整个系统挂掉。事实上,在大访问量的生产场景下,故障总是会出现的。
- 服务数量非常多,部署、管理的工作量很大。
- 开发方面:如何保证各个服务在持续开发的情况下仍然保持协同合作。
- 测试方面:服务拆分后,几乎所有功能都会涉及多个服务。原本单个程序的测试变为服务间调用的测试。测试变得更加复杂。
创始人的博客Martinfowler.com
https://martinfowler.com/articles/microservices.html
A definition of this new architectural term
The term “Microservice Architecture” has sprung up over the last few years to describe ==a particular way of designing software applications== as ==suites of independently deployable services==. While there is ==no precise definition of this architectural style==, there are certain common characteristics around organization around business capability, automated deployment, intelligence in the endpoints, and decentralized control of languages and data.
Microservices and SOA
When we’ve talked about microservices a common question is whether this is just Service Oriented Architecture (SOA) that we saw a decade ago. There is merit to this point, because the microservice style is very similar to what some advocates of SOA have been in favor of. The problem, however, is that SOA means too many different things, and that most of the time that we come across something called “SOA” it’s significantly different to the style we’re describing here, usually ==due to a focus on ESBs used to integrate monolithic applications==.
In particular we have seen so many botched implementations of service orientation - from the tendency to hide complexity away in ESB’s 5, to failed multi-year initiatives that cost millions and deliver no value, to centralised governance models that actively inhibit change, that it is sometimes difficult to see past these problems.
Certainly, many of the techniques in use in the microservice community have grown from the experiences of developers ==integrating services in large organisations==. The Tolerant Reader pattern is an example of this. Efforts to use the web have contributed, using simple protocols is another approach derived from these experiences - a reaction away from central standards that have reached a complexity that is, frankly, breathtaking. (==Any time you need an ontology to manage your ontologies you know you are in deep trouble.==)
This common manifestation of SOA has led some microservice advocates to reject the SOA label entirely, although others consider microservices to be one form of SOA [6], perhaps service orientation done right. Either way, the fact that SOA means such different things means it’s valuable to have a term that more crisply defines this architectural style.
Componentization via Services
For as long as we’ve been involved in the software industry, there’s been a desire to build systems by plugging together components, much in the way we see things are made in the physical world. During the last couple of decades we’ve seen considerable progress with large compendiums of common libraries that are part of most language platforms.
When talking about components we run into the difficult definition of what makes a component. Our definition is that a component is a unit of software ==that is independently replaceable and upgradeable==.
Microservice architectures will use libraries, but their primary way of componentizing their own software is ==by breaking down into services==. We define libraries as components that are linked into a program and called ==using in-memory function calls==, while services are ==out-of-process components== who communicate with a mechanism such as a web service request, or remote procedure call. (This is a different concept to that of a service object in many OO programs 3.)
One main reason for using services as components (rather than libraries) is that ==services are independently deployable==. ==If you have an application 4 that consists of a multiple libraries in a single process, a change to any single component results in having to redeploy the entire application.== But if that application is decomposed into multiple services, you can expect ==many single service changes to only require that service to be redeployed. ==That’s ==not an absolute==, some changes will change service interfaces resulting in some coordination, but the aim of a good microservice architecture is to minimize these through cohesive service boundaries and evolution mechanisms in the service contracts.
Another consequence of using services as components is a more explicit component interface. Most languages do not have a good mechanism for defining an explicit Published Interface. Often it’s only documentation and discipline that prevents clients breaking a component’s encapsulation, leading to overly-tight coupling between components. Services make it easier to avoid this by using explicit remote call mechanisms.
Using services like this does have downsides. Remote calls are more expensive than in-process calls, and thus remote APIs need to be coarser-grained, which is often more awkward to use. If you need to change the allocation of responsibilities between components, such movements of behavior are harder to do when you’re crossing process boundaries.
At a first approximation, we can observe that services map to runtime processes, but that is only a first approximation. A service may consist of multiple processes that will always be developed and deployed together, such as an application process and a database that’s only used by that service.
微服务设计 作者: 英 Sam Newman
微服务定义
微服务就是一些协同工作的小而自治的服务。
- 足够小 随着新功能的增加,代码库会越变越大。时间久了代码库会非常庞大,以至于想要知道该在什么地方做修改都很困难。 尽管我们想在巨大的代码库中做到清晰地模块化,但事实上这些模块之间的界限很难维护。相似的功能代码开始在代码库中随处可见,使得修复bug或实现更加困难。
经常有人问我:代码库多小才算小? 我可以给出的另一个比较老套的答案是:足够小即可,不要过小。那么换句话说,如果你不再感觉你的代码库过大,可能它就足够小了。 另外一个帮助你回答服务应该多小的关键因素是,该服务是否能够很好地与团队结构相匹配。如果代码库过大,一个小团队无法正常维护,那么很显然应该将其拆成小的。在后面关于组织匹配度的部分会对该话题做更多讨论。
- 自治性 如果系统没有很好地解耦,那么一旦出现问题,所有的功能都将不可用。有一个黄金法则是:==你是否能够修改一个服务并对其进行部署,而不影响其他任何服务==? 如果答案是否定的,那么本书剩余部分讨论的那些好处对你来说就没什么意义了。为了达到==解耦==的目的,你==需要正确地建模服务和API==。后面会针对这个话题做更多讨论。
主要好处
技术异构性、弹性(故障隔离)、拓展、简化部署、与组织结构相匹配、可组合性、对可代替性的优化
zzz:微服务强制降低了耦合性,提高了可复用性。
实施SOA时会遇到这些问题:通信协议(例如SOAP)如何选择、第三方中间件如何选择、服务粒度如何确定等,目前也存在一些关于如何划分系统的指导性原则,但其中有很多都是错误的。本书的剩余部分会分别讨论这些问题。 一些激进人士可能会认为这些厂家提出并推动SOA运动的目的不过就是想要卖更多的产品,而这些相似的产品最终破坏了SOA的目标。 现有的SOA知识==并不能帮助你把很大的应用程序划小==。它没有提到多大算大,也没有讨论如何在现实世界中有效地防止服务之间的过度耦合。由于这些点没有说清楚,所以你在实施SOA时会遇到很多问题。 在现实世界中,由于我们对项目的系统和架构有着更好的理解,所以能够更好地实施SOA,而这事实上就是微服务架构。就像认为XP或者Scrum是敏捷软件开发的一种特定方法一样,你也可以认为==微服务架构是SOA的一种特定方法==。
其他分级技术
- 共享库 无法异构、难以独立部署、缺乏明确接口
- 模块 Erlang的模块化能力确实非常惊人,但是即使我们非常幸运地能够使用具有这种能力的平台,还是会存在与使用共享库类似的缺点,即它会大大限制我们采用新技术和独立对服务进行扩展的能力,并且有可能会导致使用过度耦合的集成技术,同时也会缺乏相应的接缝来进行架构的安全性保护。 还有一个值得注意的事情是:尽管在一个单块进程中创建隔离性很好的模块是可能的,但是我很少见到真正有人能做到。==这些模块会迅速和其他代码合在一起,从而失去意义。==而进程边界的存在则能够有效地避免这种情况的发生(至少很难犯错误)。尽管我不认为这是使用进程隔离的主要原因,但是事实上确实很少有人能够在同一个进程内部做到很好的模块隔离。 除了把系统划分为不同的服务之外,你可能也想要在一个进程内部使用模块进行划分,但是仅仅使用模块划分不能解决所有的问题。如果你只使用Erlang,可能会花很长时间才能把Erlang的模块化做好,但是我怀疑大部分人不会这么做。对于剩下的人来说,==模块能够提供的好处与共享库比较类似==。
没有银弹
”规则对于智者来说是指导,对于愚蠢者来说是遵从。“ 一般认为出自Douglas Bader 做一名架构师已经很困难了,但幸运的是,通常我们不需要定义战略目标!战略目标关心的是公司的走向以及如何才能让自己的客户满意。这些战略目标的层次一般都很高,但通常不会涉及技术这个层面,一般只在公司或者部门层面制定。这些目标可以是“开拓东南亚的新市场”或者“让用户尽量使用自助服务”。因为这些都是你的组织前进的方向,所以需要确保技术层面的选择能够与之一致。
代码治理
在各个服务中使用这些标准做法会成为开发人员的负担。 我坚信应该使用简单的方式把事情做对。我见过的比较奏效的两种方式是,==提供范例==和==服务代码模板==。
如何建模服务
什么是好的服务
- 松耦合:如果做到了服务之间的松耦合,那么修改一个服务就不需要修改另一个服务。使用微服务最重要的一点是,能够==独立修改及部署单个服务而不需要修改系统的其他部分==,这真的非常重要。
- 高内聚:功能相关的服务放在一起,最好能只在一个地方修改,尽快发布。
限界上下文 bounded context
从提供的功能来考虑,而非共享数据的角度来考虑
3.5 逐步划分上下文
一开始你会识别出一些==粗粒度的限界上下文==,而这些限界上下文可能又包含一些嵌套的限界上下文。举个例子,你可以把仓库分解成为不同的部分:订单处理、库存管理、货物接受等。 当考虑微服务的边界时,首先考虑比较大的、粗粒度的那些上下文,然后当发现合适的缝隙后,再进一步划分出那些嵌套的上下文。 我见过有一种做法是,使这些嵌套的上下文==不直接对外可见==。对于外界来说,它们用的还是仓库的功能,但发出的请求其实被透明地映射到了两个或者更多的服务上,如图3-2所示。 有时候你会认为,高层次的限界上下文不应该被显式地建模成为一个服务,如图3-3所示,也就是说,不存在一个单独的仓库边界,而是把库存管理、订单处理和货物接收等这些服务分离开来。 通常==很难说哪种规则更合理==,但是你应该==根据组织结构来决定==,到底是使用==嵌套==的方法还是==完全分离==的方法。 如果订单处理、库存管理及货物接收是由不同的团队维护的,那么他们大概会希望这些服务都是顶层微服务。另一方面,如果它们都是由一个团队管理的,那么嵌套式结构会更合理。其原因在于,组织结构和软件架构会互相影响,第10章会对此做详细讨论。 另一个==倾向于嵌套式方法的原因==是,它可以使得架构更成块儿从而更好地测试。举个例子,当测试仓库的消费方服务时,不需要对仓库上下文中的每个服务进行打桩,只需要专注于粗粒度的API即可。当考虑更大范围的测试时,这也能够给你一定的单元隔离。比如,我可以有这样一种端到端测试,该测试会使用仓库上下文中的所有服务,但其他的所有协作者可以做打桩处理。第7章会对测试和隔离做更多讨论。
4 集成
4.1 寻找理想的集成技术
避免破坏性修改、保证API的技术无关性、使服务易于消费方使用、隐藏内部实现细节
4.3 共享数据库
数据库集成会遇到一些困难。 首先,这使得外部系统能够查看内部实现细节,并与其绑定在一起。数据库是一个很大的共享API,但同时也非常不稳定。 其次,消费方与特定的技术选择绑定在了一起。破坏了低耦合。 最后,对数据库进行操作的相似逻辑可能出现在很多服务中,要分别部署。破坏了内聚性。
4.4 同步与异步
请求/响应:发起请求,注册回调。服务端完成后调用回调。RPC, REST 基于事件:客户端发布事件,服务端(订阅者)响应该事件。该类系统天生就是异步的。 zzz:响应该事件是否就相当于调用回调?
4.5 编排(orchestration)与协同(choreography)
orchestration:依赖于某个中心大脑指导并驱动整个流程。 choreography:仅仅告知各部分的职责,不管实现细节。
这意味着,需要做一些额外的工作来监控流程,以保证其正确地进行。举个例子,如果积分账户存在的bug导致账户没有创建成功,程序是否能够捕捉到这个问题?处理该问题的一种方法是,构建一个与图4-2中展示的业务流程相匹配的监控系统。 实际的监控活动是针对每个服务的,但最终需要把监控的结果映射到业务流程中。在这个流程图中我们可以看出系统是如何工作的。 通常来讲,我认为使用==协同的方式可以降低系统的耦合度==,并且你能更加灵活地对现有系统进行修改。但是,确实==需要额外的工作来对业务流程做跨服务的监控==。我还发现大多数重量级的编排方案都非常不稳定且修改代价很大。基于这些事实,我倾向于使用协同方式,在这种方式下每个服务都足够聪明,并且能够很好地完成自己的任务。
4.6 远程过程调用RPC
RPC优点:易于使用 缺点:
- 技术耦合:与平台紧密绑定
- 本地调用与运程调用实际上并不相同:网络并不总是可靠的。
- 脆弱性?不易修改,客户端与服务端绑定。
桩代码就是用来代替某些代码的代码。
4.7 REST
zzz:类似于一切皆文件,REST中一切皆资源。 [[WebService-protocols (REST,WSDL,SOAP,UDDI)]]
4.9 服务即状态机
不论RPC还是REST,状态机的概念都是十分有用的。
4.14 UI
用户界面是连接各个微服务的工具。 桌面端胖客户端 -> web时代初,薄UI 主要依赖GET/POST -> 依赖JS的动态UI,又胖了
- 数字化界面:各个API/服务看作绳索,UI是将其编织起来
- API组合
- 这种方式有一些问题。首先==很难为不同的设备定制不同的响应==。比如,移动商店所需要的数据和帮助台应用所需要的数据就有可能不同。一个解决方案是,允许客户指定它想要哪些字段,但这就需要每个服务都支持这种交互方式。
- 另一个关键的问题是:==谁来创建用户界面?==维护服务的人往往不是服务的使用者。举个例子,如果UI是另一个团队创建的,我们可能==会退回到以前那种分层合作模式,在这种模式下即使很小的修改都需要多个团队的参与==。
- 这种通信模式非常繁琐。与服务之间过多的交互对移动设备来说会有些吃力,而且对使用流量套餐的用户来说也很不利!使用API入口(gateway)可以很好地缓解这一问题,在这种模式下多个底层的调用会被聚合成为一个调用,当然它也有一定的局限性,后面会做讨论。
- UI片段组合:可能会遇到风格不统一的问题
- backend for frontend (BFF): 尽量保证一个后端只为一个应用提供UI。与任何一种聚合层类似,使用这种方法的==风险在于包含不该包含的逻辑==。业务逻辑应该处在服务中,而不应该泄露到这一层。这些BFF应该仅仅包含与实现某种特定的用户体验相关的逻辑。
- 混合方式:关键是要保证底层服务能力的聚合性。
4.16 小结
如何保证微服务之间的低耦合?
- 无论如何避免数据库集成
- 理解REST和RPC之间的取舍,但总是使用REST作为请求/响应模式的起点
- 相比编排,优先选择协同 (同步/异步)
- 避免破坏性修改
- 理解Postel法则
- 使用容错性读取器
- 将用户界面视为一个组合层
5 分解单块系统
5.1 关键是接缝
限界上下文就是很好的接缝
5.3 分解单块系统的原因
决定把单块系统变小是一个很好的开始。但我强烈建议你慢慢开凿这些系统。 增量的方式可以让你在进行的过程中学习微服务,同时也可以限制出错所造成的影响(相信我,你一定会犯错的! )。 把单块系统想象成为一块大理石,我们可以把整块石头炸开,但这样做的结果通常不好。增量开凿的方式更合理。所以如果我准备开始对单块系统做分离,要从哪里下手呢?接缝已经找到了,那么应该先把哪个拉出来呢?最好考虑一下把哪部分代码抽取出去得到的收益最大,而不是为了抽取而抽取。接下来考虑一些指导因素。
12.1 微服务的原则
围绕业务概念建模, 自动化文化, 隐藏内部实现细节, 一切去中心化,独立部署, 故障隔离, 高度可观察